A Strategic and Technical Framework for African Institutions
Executive Summary
Artificial intelligence is not simply a tool layer that organisations bolt onto existing infrastructure. It is a fundamental re-architecture of how data moves, decisions are made, and value is created. For African institutions navigating legacy systems, constrained technical capacity, and rapidly evolving regulatory environments, understanding the architectural principles that govern intelligent systems is no longer optional it is a strategic imperative.
This article synthesises the five foundational pillars of AI architecture design: foundational system design, modularity, layered model development, data pipeline orchestration, and scalability. Together, these principles constitute the blueprint that distinguishes an AI initiative that delivers sustained institutional value from one that collapses under operational weight.
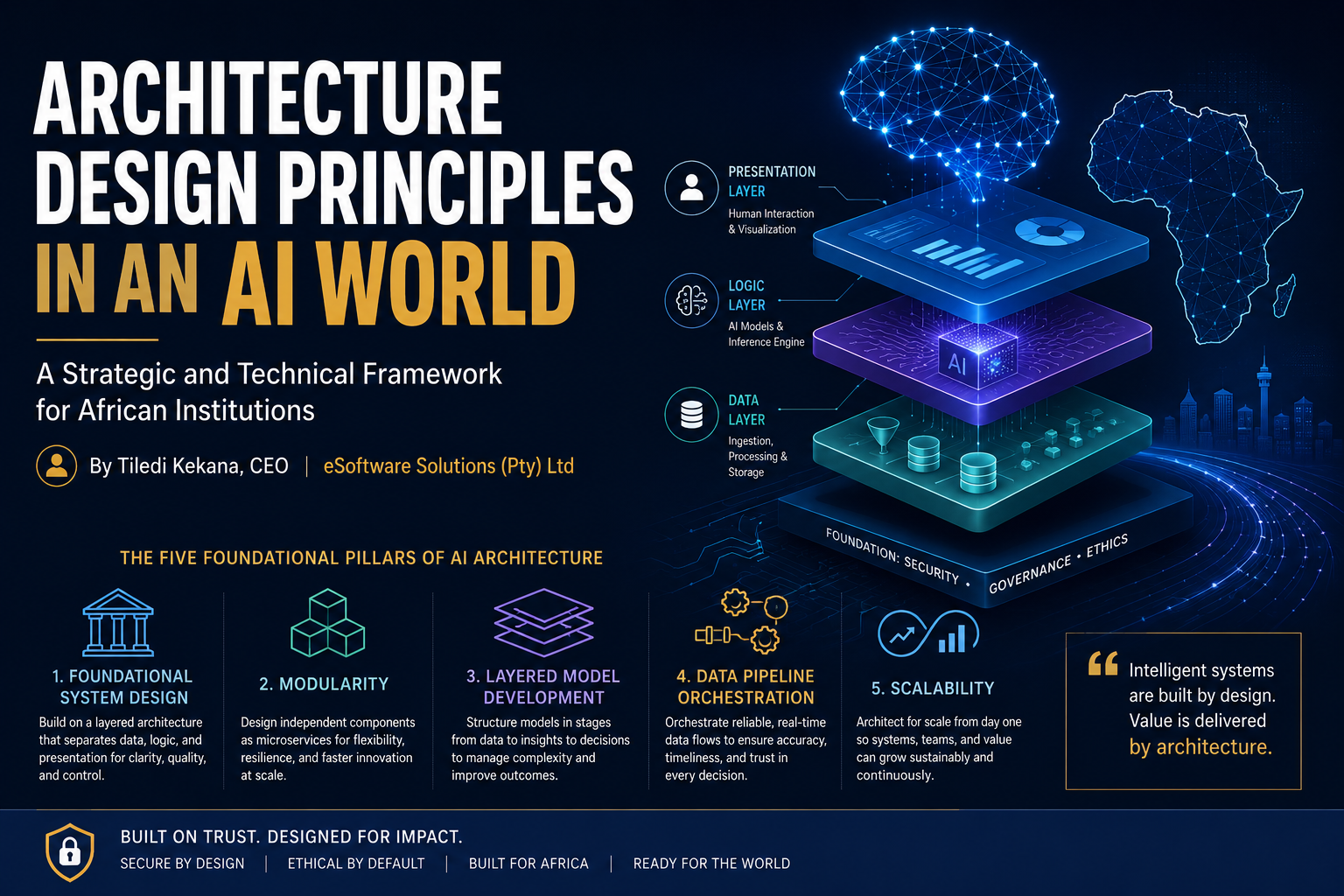
1. Foundational AI System Architecture: Designing for Complexity
Every effective AI system begins with a deliberate architectural decision. Before a single model is trained or a single API endpoint is exposed, the architect must interrogate the problem domain with precision: What data types are involved? What is the task complexity? What performance envelope is the institution prepared to sustain operationally?
The most durable framework for answering these questions is the layered architecture model, which partitions an AI system into three discrete functional strata. The data layer governs ingestion and preprocessing the quality-critical foundation upon which all downstream intelligence rests. The logic layer houses the core AI algorithms and model inference engines. The presentation layer manages human interaction, surfacing outputs to decision-makers in forms they can act upon.
Google’s TensorFlow Extended (TFX) exemplifies this principle in production: data validation, feature engineering, and model deployment are demarcated as separate entities, enabling independent scaling and optimisation at each layer without cascading disruption.
This architectural philosophy extends to tooling selection. Apache Kafka enables real-time data pipelines capable of processing high-velocity information streams with minimal latency a critical capability for financial services institutions where decision windows are measured in milliseconds. TensorFlow and PyTorch provide the model-building infrastructure, each with distinct strengths: TensorFlow for production-scale deployment, PyTorch for rapid experimental iteration.
The operationalisation of AI systems managing models in production at enterprise scale falls under Machine Learning Operations (MLOps). Platforms such as Kubeflow, built atop Kubernetes, provide continuous integration, deployment, and monitoring of AI workflows, ensuring that models do not merely perform well at launch but maintain accuracy as the data environment evolves.
For institutions in financial services specifically, the architecture must simultaneously address ethical and security imperatives. Techniques such as differential privacy and federated learning allow AI models to derive institutional insight from sensitive data without exposing individual records a non-negotiable requirement for regulatory compliance and stakeholder trust.
2. Modularity: The Strategic Imperative of Independent Components
Modularity is perhaps the most consequential architectural decision an institution will make when designing AI systems, yet it is frequently underestimated as a technical nicety rather than recognised as a strategic necessity. The distinction matters enormously in practice: a monolithic AI application, designed as a single integrated entity, renders every component change a system-wide risk event. A modular architecture transforms that same change into an isolated, manageable operation.
Industry data is unambiguous on this point: 61% of organisations with mature AI practices prioritise modularity, compared to only 39% in nascent phases. Modularity is not where you arrive it is what separates organisations that scale from those that stall.
The most robust implementation of modularity in AI systems is the microservices architecture, which decomposes an application into a suite of loosely coupled, independently operable services. In a natural language processing system, for instance, tokenisation, sentiment analysis, and language translation function as discrete services coordinated through well-defined APIs each deployable, scalable, and replaceable without disrupting the others.
The infrastructure enablers of modularity are Docker and Kubernetes. Docker packages each modular service with its complete environment dependencies, ensuring consistency across deployment landscapes regardless of the underlying hardware or cloud environment. Kubernetes then orchestrates these containers automating initiation, scaling, and operational updates with the kind of reliability that enterprise workloads demand.
AI-driven recommendation system offers the definitive real-world validation of this approach. Processing petabytes of data daily through a microservices architecture. These engines achieve continuous service delivery and efficient request handling at a scale that no monolithic design could sustain. The lesson for African institutions is direct: modularity is not a luxury of hyperscale it is the foundation of any AI system designed to grow.
For machine learning practitioners, modularity finds expression in the frameworks themselves. PyTorch’s enables developers to configure reusable model components standardised building blocks that accelerate development cycles and reduce the cost of experimentation. The Model-View-Controller (MVC) design pattern further extends this principle by separating data models, user interfaces, and control logic as independent entities, enabling cleaner development and more responsive adaptation to changing requirements.
3. Layered Design in AI Model Development: From Architecture to Intelligence
If modularity governs how AI systems are structured externally, layered design governs how intelligence is constructed internally. The layered approach organises model architecture into discrete computational strata, each responsible for a specific class of transformation from raw input through progressive abstraction to actionable output.
This principle is most visibly realised in deep neural networks. Convolutional Neural Networks (CNNs) employ convolutional layers to manage spatial data hierarchies, incrementally recognising patterns from simple edges and textures through to complex shapes and objects a capability that underpins applications as diverse as medical imaging diagnostics and autonomous vehicle navigation. Recurrent Neural Networks (RNNs) apply the same principle to sequential data, with recurrent layers preserving temporal context across time steps.
AlphaGo’s defeat of world champion Go players stands as the most dramatic demonstration of layered design’s power: a deep neural network with multiple layers evaluated board positions and determined optimal moves across a solution space too vast for any rule-based system to navigate.
The impact of depth on performance is empirically established. Research on ResNet a deep residual network demonstrated that increasing the number of layers enhanced model accuracy in a statistically significant way, setting a precedent for how layered design drives AI performance breakthroughs. This finding has since been replicated across domains and is now embedded in the design philosophy of the most capable AI systems in deployment.
For Natural Language Processing, the Transformer architecture exemplified by BERT and GPT represents the pinnacle of layered design. Attention mechanisms capture contextual relationships between words with each successive layer, refining input representation progressively until the model achieves language understanding and generation capabilities that approach human-level fluency.
Transfer learning adds a further dimension of strategic value to layered design. By freezing certain layers of a pre-trained model and retraining only the upper layers on new domain-specific data, institutions can deploy high-capability AI systems without the prohibitive computational cost of training from scratch. For African organisations with constrained infrastructure budgets, this represents a direct path to enterprise-grade AI capability.
The frameworks that operationalise layered design TensorFlow via its Keras API, and PyTorch via dynamic computational graphs provide both the abstraction layer for rapid prototyping and the control depth required for production optimisation. Visualisation tools such as TensorBoard close the loop, providing real-time insight into model performance across training epochs and enabling the iterative refinement cycle that separates an accurate model from a merely functional one.
4. Orchestrating Data Flow in AI Pipelines: From Ingestion to Deployment
An AI model is only as capable as the pipeline that feeds it. The orchestration of data flow from initial ingestion through preprocessing, storage, training, evaluation, deployment, and ongoing monitoring constitutes the operational backbone of any production AI system. Each phase is a potential failure point; each phase, executed well, is a compounding advantage.
Data Ingestion
The pipeline begins with ingestion, where raw data is collected from diverse sources databases, IoT devices, web services, transactional systems. The defining challenge at this stage is handling heterogeneous data formats while maintaining quality and continuity. Apache Kafka, as a distributed streaming platform, provides the throughput and low latency required for large-scale, time-sensitive AI applications. Apache Flume complements this capability for log and event data aggregation.
Preprocessing
Data ingested from the real world is invariably imperfect. Preprocessing cleaning, transforming, and structuring data for model consumption is where the quality of an AI system’s outputs is fundamentally determined. Apache Spark’s distributed computing capability, combined with Pandas’ data manipulation precision, enables institutions to process large datasets efficiently while maintaining the data integrity that accurate models require.
Storage Architecture
The choice between data warehousing and data lakes is not merely technical it reflects an institution’s analytical philosophy. Data warehouses such as Amazon Redshift and Google BigQuery offer structured, query-optimised environments suited to rapid analysis of defined datasets. Data lakes built on Hadoop or Amazon S3 provide the flexibility to store both structured and unstructured data at scale, preserving raw information for future use cases that cannot yet be fully anticipated.
Training, Evaluation, and Deployment
Model training demands significant computational resources and careful data management. The continuous integration and deployment (CI/CD) paradigm, implemented through tools like Jenkins, ensures that models are tested rigorously and updated systematically as data patterns evolve preventing the silent performance degradation that afflicts AI systems operating without governance discipline. Docker and Kubernetes then enable production deployment with the scalability and fault tolerance that enterprise workloads require.
Monitoring
Deployment is not the end of the pipeline it is the beginning of a new operational responsibility. Data drift, the change in statistical properties of input data over time, is the most insidious threat to model performance in production. Prometheus and Grafana provide the monitoring infrastructure to detect anomalies promptly, enabling AI teams to intervene before performance degradation reaches users.
Netflix’s data pipeline, processing petabytes daily to deliver personalised content recommendations, demonstrates what a well-integrated data flow architecture achieves at scale: not merely accurate outputs, but a system that learns continuously and improves in proportion to the data it receives.
5. Scalability: Engineering AI Systems for Growth
Scalability is the architectural property that determines whether an AI investment compounds in value or collapses under its own success. An AI system that performs admirably at pilot scale but degrades under production load is not a technical limitation it is a strategic failure that could have been designed away from the outset.
Scalable data management begins with distributed computing frameworks. Apache Hadoop and Apache Spark partition extensive datasets into smaller segments processed in parallel across machine clusters, delivering the throughput required for AI systems that must ingest and process data faster than any single machine could handle.
Cloud infrastructure provides the elasticity that scalable AI systems require. AWS, Google Cloud, and Microsoft Azure.
The horizontal versus vertical scaling decision deserves deliberate attention. Vertical scaling enhancing the memory and processing power of existing machines reaches hard limits and represents a single point of failure. Horizontal scaling adding machines to the cluster offers greater fault tolerance and more linear cost growth. For institutions anticipating sustained AI workload growth, horizontal scaling is the architecturally sound default.
Containerisation, through Docker and Kubernetes, ensures that AI applications maintain consistent environments as they scale across varied infrastructure. Edge computing introduces an additional dimension: by processing data closer to the source, institutions can reduce latency and bandwidth consumption for AI applications that must operate at the network periphery a capability of particular relevance for African institutions where connectivity infrastructure varies significantly across geographies.
As AI systems scale, they present an increasingly attractive target for cyber threats. Encryption, access controls, and compliance with applicable regulations are not afterthoughts they are architectural requirements that must be embedded in the system design from the first line of infrastructure code.
Performance metrics latency, throughput, and model accuracy must be monitored continuously as systems scale. Apache JMeter for load testing and Grafana for real-time performance monitoring provide the instrumentation layer that enables proactive management rather than reactive crisis response.
6. The Architecture Imperative for African Institutions
The five principles examined in this article foundational system design, modularity, layered model development, data pipeline orchestration, and scalability are not independent considerations. They constitute an integrated architectural philosophy that must be applied holistically if an AI initiative is to deliver sustainable institutional value.
For African institutions specifically, the architectural stakes are compounded by contextual realities that Western-designed frameworks frequently underestimate: legacy system estates that cannot simply be replaced, technical talent pipelines that are still maturing, connectivity infrastructure that varies by geography, regulatory environments that are evolving in real time, and procurement processes that extend implementation timelines.
The appropriate response to these constraints is not a reduced ambition for AI architecture it is a more deliberate one. Modularity allows institutions to build incrementally, deploying capability in stages rather than betting everything on a single implementation. Layered design enables transfer learning approaches that maximise capability without requiring the computational budgets of a hyperscaler. Scalable infrastructure, built on cloud platforms and containerised deployments, allows institutions to right-size their investment at each growth stage. The organisations that will lead Africa’s AI transformation over the next decade are not those with the largest technology budgets. They are those with the clearest architectural thinking the discipline to design systems that are modular enough to evolve, scalable enough to grow, and principle